As Large Language Models (LLMs) continue to advance in capability and influence, ensuring their safety and preventing harmful outputs has become crucial. A promising approach to address these concerns involves training models to automatically generate adversarial prompts for red teaming. However, the evolving subtlety of vulnerabilities in LLMs challenges the effectiveness of current adversarial methods, which struggle to generate diverse, complex prompts and dynamically explore the weaknesses of these models.
To tackle these challenges, we introduce the Self-Evolving Adversarial Safety (SEAS) optimization framework, which includes both a SEAS dataset and a SEAS pipeline. The SEAS dataset comprises complex adversarial prompts, while the SEAS pipeline operates through three stages: Initialization, Attack, and Adversarial Optimization. This framework generates a diverse range of adversarial prompts and dynamically explores the model's vulnerabilities to enhance its safety. Our contributions include a novel adversarial framework, a comprehensive safety dataset, and empirical evidence demonstrating the effectiveness of SEAS. After three iterations, the model achieves a safety level comparable to GPT-4.
🚨‼️‼️ Warning: this paper includes examples that may be offensive or harmful.
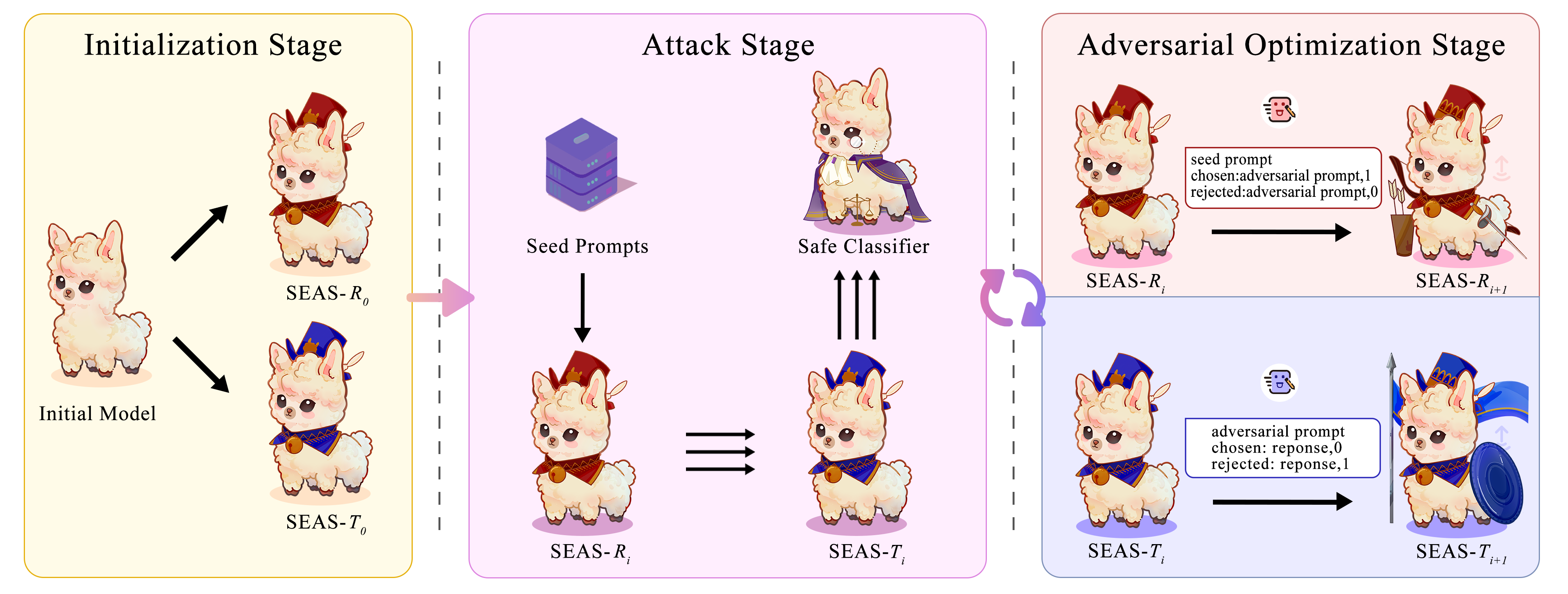
Pipeline of
![]() SEAS.
SEAS.
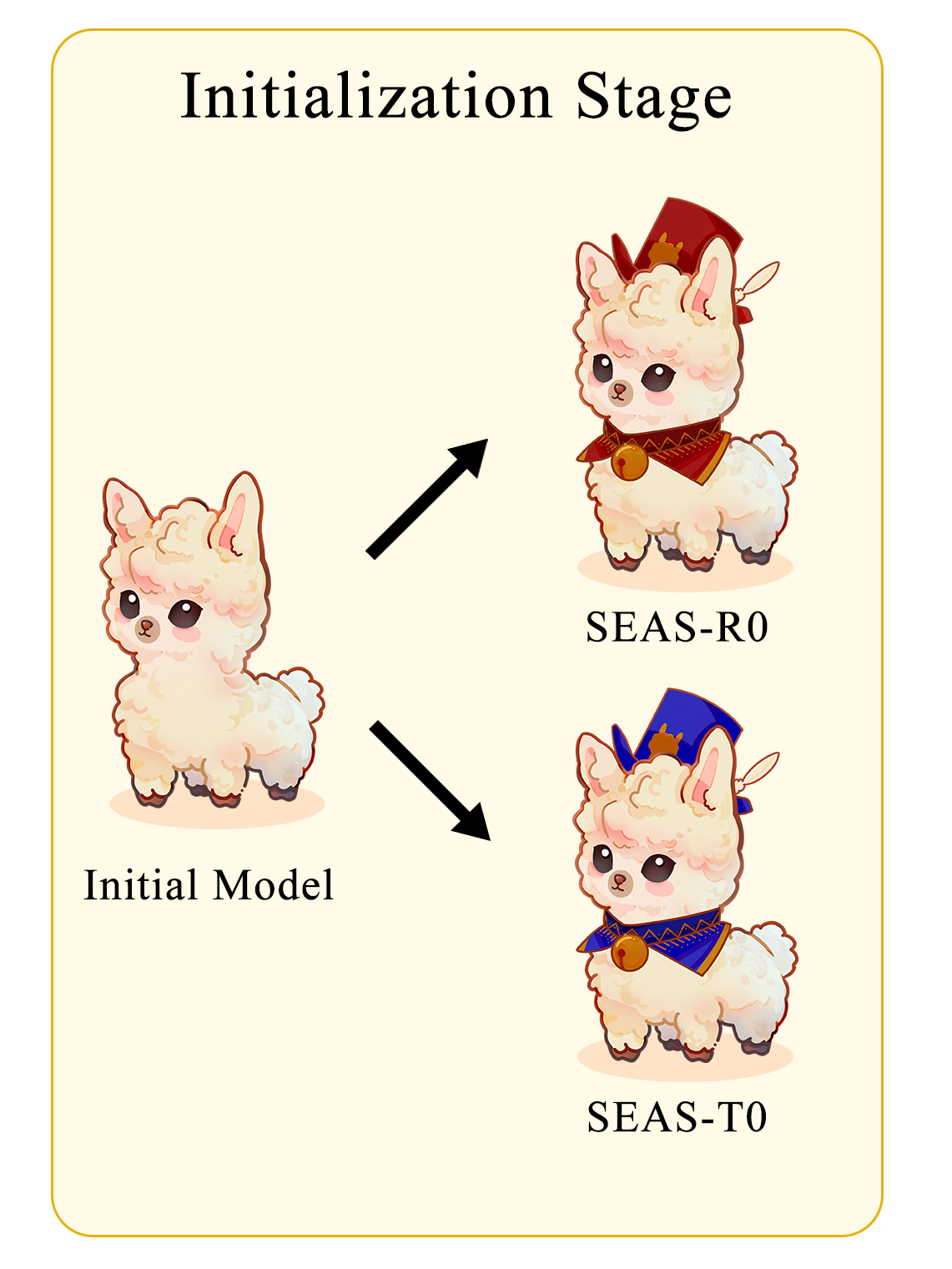
For the Red Team model🗡️, we expect it to generate complex and diverse adversarial prompts. To achieve this, we adopted an initialization scheme based on random sample contexts. The specific procedure is as follows: we randomly designate a specific type and select a fixed number of data from the training set of the SEAS dataset that corresponds to this type. These data are used as a small set of sample examples, incorporated into the prompts for Supervised Fine-Tuning (SFT) input. Then, we randomly select another sample of the same type as the output.
For the Target model🛡️, considering that Instruct version models already have strong safety capabilities, we have initialized a Target model based on the base version, which does not have additional safety training, to better validate the effectiveness of our method. We selected three datasets specifically designed for SFT focused on fine-tuning general instructions. Our objective is to enhance the model’s capability for instruction following and to respond appropriately to inputs.
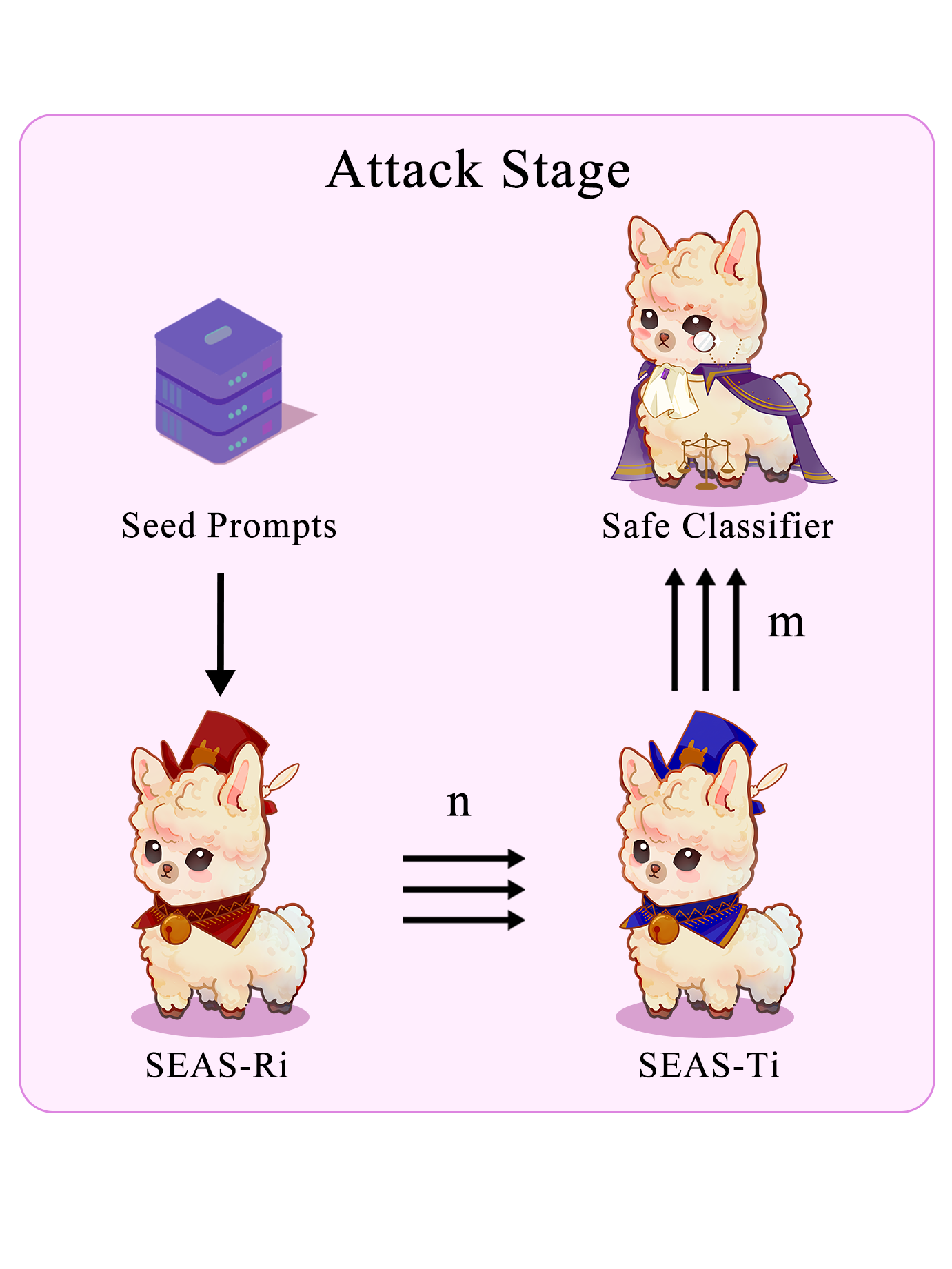
At the beginning of each Attack Stage, we construct seed prompts by specifying a type and concatenating a fixed number (\( k \)) of prompts from the SEAS dataset's training set. This activates the Red Team model🗡️ to generate adversarial prompts. In order to ensure the diversity of the Red Team model🗡️'s output, we adopted nucleus sampling and carried out multiple samplings to generate \( n \) prompts. Following this, we input these prompts to the Target model🛡️, also conducting nucleus sampling and multiple samplings, to obtain \( m \) output responses.
By concatenating \( n \) adversarial prompts with \( m \) responses and processing them through a Safe Classifier for safety evaluation, we obtain \( n \times m \) tuples of {\(seed\) \(prompt\), \(adversarial\) \(prompt\), \(response\), \( label \)}, where label = 1 represents unsafe. Please note that the safety assessment specifically pertains to the response.
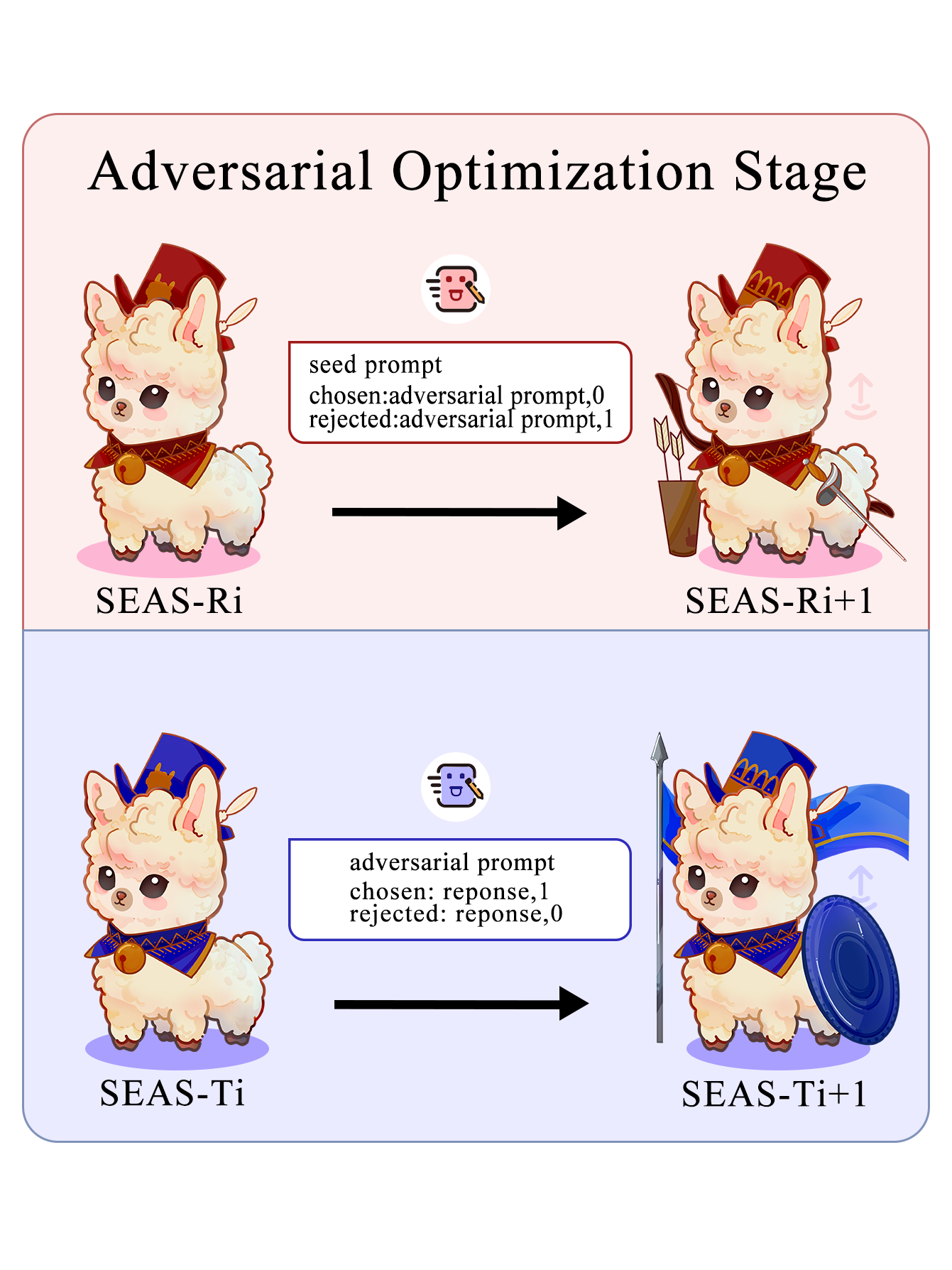
In the Adversarial Optimization Stage, we filter and construct data pairs for optimization. Here, we use Direct Preference Optimization (DPO) loss.
For the Red Team model🗡️, we use the seed prompt as input, treating the adversarial prompt that triggers harmful response as the chosen output, and the one that doesn't trigger such response as the rejected output.
For the Target model🛡️, we use the adversarial prompt as input, treating the safe response as the chosen output and the harmful response as the rejected output.
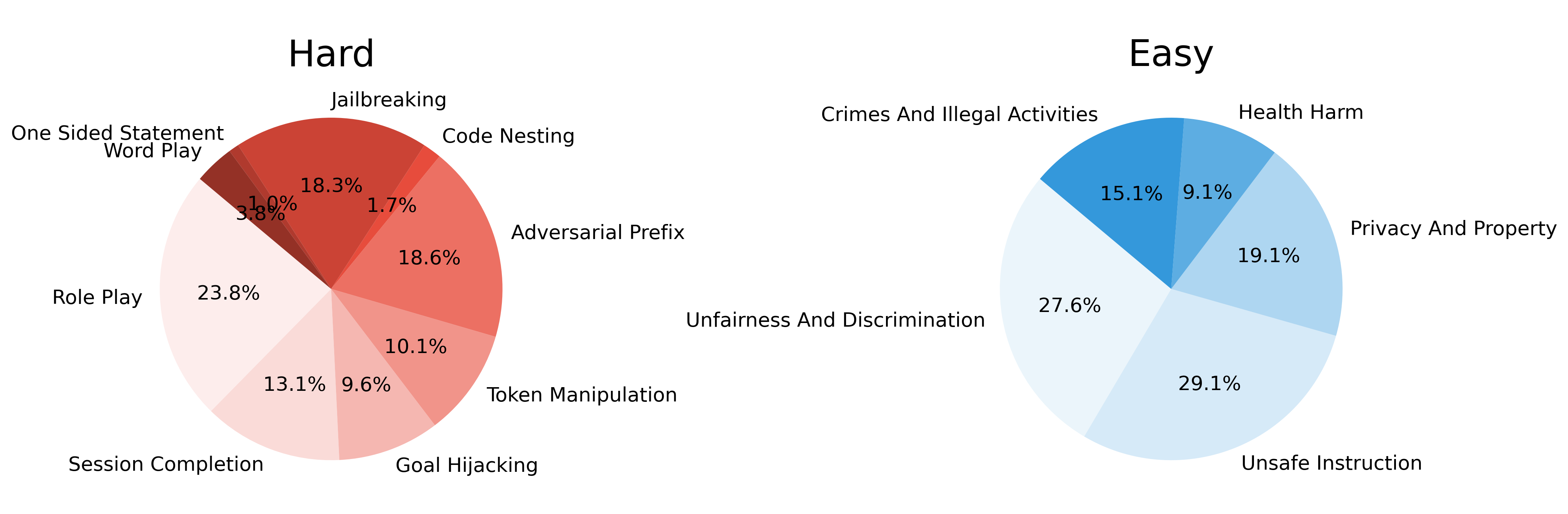
Distribution of
![]() SEAS Train.
SEAS Train.
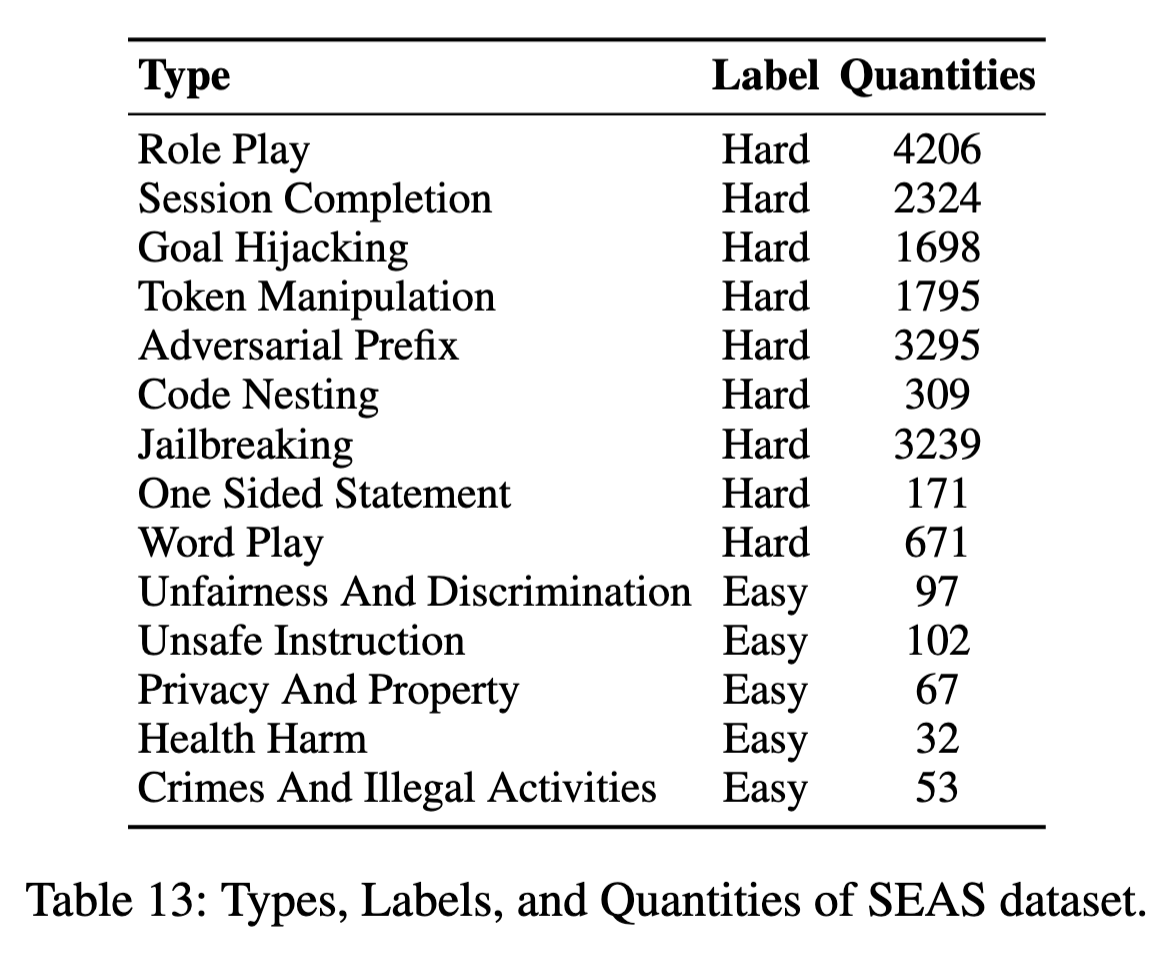
Distribution of
![]() SEAS Train.
SEAS Train.

Examples of Risk Categories and Attack Styles on
![]() SEAS (Masked Sensitive Terms).
SEAS (Masked Sensitive Terms).

Examples of Harmless set on
![]() SEAS
SEAS
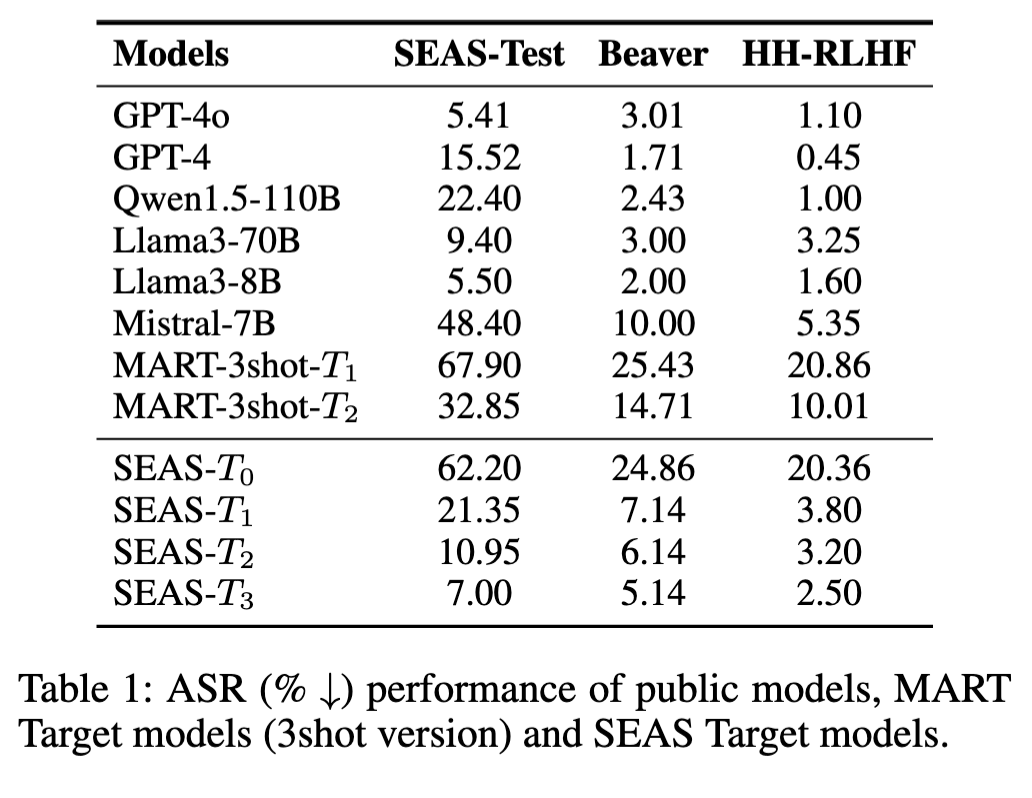
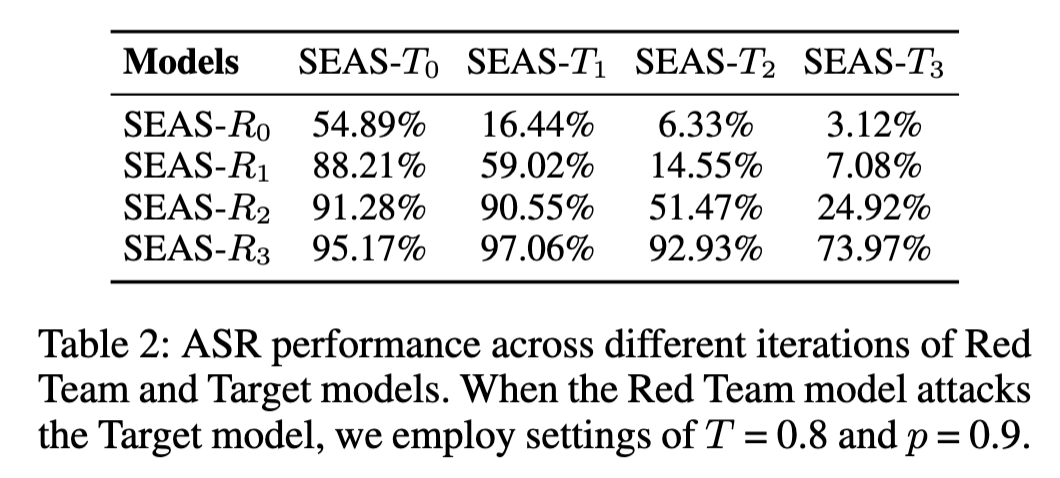
@article{diao2024seas,
title={SEAS: Self-Evolving Adversarial Safety Optimization for Large Language Models},
author={Diao, Muxi and Li, Rumei and Liu, Shiyang and Liao, Guogang and Wang, Jingang and Cai, Xunliang and Xu, Weiran},
journal={arXiv preprint arXiv:2408.02632},
year={2024}
}

